Tutorial#
![]()
In this tutorial we demonstrate the use of the CoRegTor tool to find transcription co regulators for a gene from gene expression data.
Objective#
The aim of this tutorial is to find potential co-regulators of the gene GFAP by analyzing tissue gene expression data for Frontal cortex in adult brain.
Step 1 : Install and import the CoRegTor package and other dependencies#
Using pip, pip install coregtor .
Or poetry install coregtor to add the package as a dependency in your project
# Install coregtor if not already installed, then import it
try:
import coregtor
import coregtor.utils as ut
except ImportError:
%pip install coregtor
import coregtor
# Additional imports
from pathlib import Path
import pandas as pd
Step 2 : Get data and load it#
Let’s gather all the data we require:
Gene Expression data
ge_brain.gct. This file contains tissue gene expression data for the Frontal Cortex (BA9) in an adult brain. The data is downloaded from the GTEx portalList of transcription factors
human_tf.txt: This file was downloaded from aertslab.org
We load this data in dataframes. Now we are ready to use CoRegTor!
base_path = Path("docs/temp") # UPDATE THIS
data_file_path = Path(base_path/"brain_ge.gct") # UPDATE THIS
tf_file_path = Path(base_path/"human_tf.txt") # UPDATE THIS
target_gene_name = "GFAP" # the gene we are interested in
# load data
ge_data = ut.exp.read_GE_data(file_path=data_file_path) # this is just a utility method you dont have to use this if you already have you gene expression data ready in a dataframe
tf_data = pd.read_csv(tf_file_path, names=["gene_name"], header=None)
ge_data
| gene_name | DDX11L1 | WASH7P | MIR6859-1 | MIR1302-2HG | FAM138A | OR4G4P | OR4G11P | OR4F5 | ENSG00000238009 | CICP27 | ... | MT-ND4 | MT-TH | MT-TS2 | MT-TL2 | MT-ND5 | MT-ND6 | MT-TE | MT-CYB | MT-TT | MT-TP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| sample_name | |||||||||||||||||||||
| GTEX-1117F-0011-R10b-SM-GI4VE | 0.000000 | 3.57928 | 0.0 | 0.093825 | 0.000000 | 0.000000 | 0.028731 | 0.046554 | 0.039501 | 0.058675 | ... | 49762.2 | 1.177570 | 2.754330 | 0.000000 | 7311.39 | 4788.56 | 6.47666 | 28676.5 | 3.077750 | 1.19489 |
| GTEX-111FC-0011-R10a-SM-GIN8G | 0.000000 | 2.32926 | 0.0 | 0.025333 | 0.000000 | 0.052233 | 0.031030 | 0.016759 | 0.000000 | 0.031684 | ... | 44692.0 | 0.953824 | 0.000000 | 1.544930 | 6831.00 | 5164.36 | 6.67677 | 26950.9 | 1.661970 | 3.54879 |
| GTEX-117XS-0011-R10b-SM-GIN8Z | 0.000000 | 4.79425 | 0.0 | 0.000000 | 0.046843 | 0.067977 | 0.020191 | 0.043622 | 0.013880 | 0.032987 | ... | 39249.9 | 0.827551 | 0.967814 | 1.206360 | 5603.53 | 3585.51 | 6.20663 | 20794.9 | 0.432584 | 2.93902 |
| GTEX-1192W-0011-R10b-SM-GHWOF | 0.000000 | 3.83774 | 0.0 | 0.032159 | 0.045693 | 0.000000 | 0.039392 | 0.053189 | 0.013539 | 0.000000 | ... | 50750.5 | 1.614480 | 2.832190 | 1.176750 | 9433.33 | 7697.90 | 12.51220 | 23405.4 | 1.265900 | 3.68601 |
| GTEX-1192X-0011-R10a-SM-DO941 | 0.040388 | 1.47233 | 0.0 | 0.040318 | 0.000000 | 0.000000 | 0.049385 | 0.040010 | 0.050922 | 0.000000 | ... | 31566.9 | 2.024070 | 0.591784 | 0.983528 | 4424.64 | 3568.41 | 4.55416 | 14051.5 | 0.529019 | 1.54038 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| GTEX-ZVZQ-0011-R10b-SM-51MRT | 0.017553 | 1.91964 | 0.0 | 0.070089 | 0.000000 | 0.180647 | 0.064389 | 0.092738 | 0.044262 | 0.043831 | ... | 44939.6 | 3.078850 | 1.543150 | 2.137230 | 7019.94 | 6874.29 | 16.71380 | 24296.2 | 1.379490 | 2.23152 |
| GTEX-ZXG5-0011-R10a-SM-57WDD | 0.000000 | 1.07536 | 0.0 | 0.036646 | 0.000000 | 0.000000 | 0.044887 | 0.084853 | 0.000000 | 0.000000 | ... | 62226.7 | 2.759570 | 1.613650 | 4.469730 | 11407.90 | 11061.80 | 15.17770 | 38732.2 | 1.442500 | 1.86677 |
| GTEX-ZYFD-0011-R10a-SM-GPI91 | 0.000000 | 2.71020 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.037432 | 0.000000 | 0.000000 | 0.030577 | ... | 43740.3 | 0.000000 | 2.691290 | 0.745473 | 6574.39 | 5241.85 | 9.20498 | 24934.3 | 0.000000 | 1.55672 |
| GTEX-ZYY3-0011-R10a-SM-GNTAZ | 0.015919 | 3.29538 | 0.0 | 0.000000 | 0.000000 | 0.065533 | 0.058395 | 0.031540 | 0.066902 | 0.079502 | ... | 40835.8 | 1.196680 | 0.933006 | 3.101260 | 6228.45 | 5626.94 | 10.37120 | 20992.5 | 5.004310 | 2.83332 |
| GTEX-ZZPT-0011-R10b-SM-GPI8B | 0.000000 | 2.85899 | 0.0 | 0.049821 | 0.000000 | 0.000000 | 0.030513 | 0.000000 | 0.041949 | 0.024925 | ... | 40128.3 | 1.250570 | 0.000000 | 1.215350 | 8300.34 | 8785.10 | 28.13790 | 30362.8 | 2.614830 | 3.80689 |
269 rows × 59033 columns
tf_data
| gene_name | |
|---|---|
| 0 | ZNF354C |
| 1 | KLF12 |
| 2 | ZNF143 |
| 3 | ZIC2 |
| 4 | ZNF274 |
| ... | ... |
| 1887 | ZNF826P |
| 1888 | ZNF827 |
| 1889 | ZNF831 |
| 1890 | ZRSR2 |
| 1891 | ZSWIM1 |
1892 rows × 1 columns
Step 3 : Create Ensemble model#
The first step in the process is to generate a random forest ensemble model using the gene expression data that predicts the expression value of the gene “GFAP” based on all other genes.
Since we are interested in identifying potential transcription co regulators, we filter the data to include only transcription factors. We use the create_model_input function for filtering and preparing the input for training. It takes a dataframe t_factors which should have a column gene_name listing the transcription factors to consider. The function outputs a tuple containing 2 data frames: X with the feature genes and Y with the target gene. These can then be passed to the generate_model function.
# first generate the training input for the model
X,Y = coregtor.create_model_input(ge_data,target_gene_name,tf_data)
# use the training data to create a model
model = coregtor.create_model(X,Y,"rf",{"n_jobs":8})
model
RandomForestRegressor(n_jobs=8)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| n_estimators | 100 | |
| criterion | 'squared_error' | |
| max_depth | None | |
| min_samples_split | 2 | |
| min_samples_leaf | 1 | |
| min_weight_fraction_leaf | 0.0 | |
| max_features | 1.0 | |
| max_leaf_nodes | None | |
| min_impurity_decrease | 0.0 | |
| bootstrap | True | |
| oob_score | False | |
| n_jobs | 8 | |
| random_state | None | |
| verbose | 0 | |
| warm_start | False | |
| ccp_alpha | 0.0 | |
| max_samples | None | |
| monotonic_cst | None |
Step 4 : Generating tree paths#
The genes on the root node are important. These also serve as potential regulators in other tree based GRN inference methods.
Forest based ensemble methods contains multiple decision tress. We want to analyze the structure of the trees in the model.
For each tree, there exists multiple root to leaf paths. We first enumerate all the paths in all the trees in the model.
all_paths = coregtor.tree_paths(model,X,Y)
all_paths
| tree | source | target | path_length | node1 | node2 | node3 | node4 | node5 | node6 | ... | node9 | node10 | node11 | node12 | node13 | node14 | node15 | node16 | node17 | node18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | HMBOX1 | GFAP | 11 | YBX1 | SP110 | GATA2 | DBX2 | VENTX | DBX2 | ... | ZNF284 | KLF3 | None | None | None | None | None | None | None | None |
| 1 | 0 | HMBOX1 | GFAP | 13 | YBX1 | SP110 | GATA2 | DBX2 | VENTX | DBX2 | ... | RBPJ | EGR3 | KLF6 | ZBTB41 | None | None | None | None | None | None |
| 2 | 0 | HMBOX1 | GFAP | 11 | YBX1 | SP110 | GATA2 | DBX2 | VENTX | DBX2 | ... | VENTX | ADARB1 | None | None | None | None | None | None | None | None |
| 3 | 0 | HMBOX1 | GFAP | 9 | YBX1 | SP110 | ZNF653 | VAX2 | SOX2 | HOXA4 | ... | None | None | None | None | None | None | None | None | None | None |
| 4 | 0 | HMBOX1 | GFAP | 9 | YBX1 | SP110 | ZNF653 | VAX2 | NKX2-8 | ZNF595 | ... | None | None | None | None | None | None | None | None | None | None |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 10972 | 99 | ZNF114 | GFAP | 6 | HDAC1 | POU2F1 | ZNF345 | NFKB2 | ZNF16 | None | ... | None | None | None | None | None | None | None | None | None | None |
| 10973 | 99 | ZNF114 | GFAP | 9 | HDAC1 | DLX1 | LBX2 | DMRT3 | HAND1 | PAX5 | ... | None | None | None | None | None | None | None | None | None | None |
| 10974 | 99 | ZNF114 | GFAP | 7 | HDAC1 | DLX1 | LBX2 | TET1 | ZFP57 | SOHLH2 | ... | None | None | None | None | None | None | None | None | None | None |
| 10975 | 99 | ZNF114 | GFAP | 6 | HDAC1 | POU2F1 | ZNF345 | NFKB2 | MSGN1 | None | ... | None | None | None | None | None | None | None | None | None | None |
| 10976 | 99 | ZNF114 | GFAP | 11 | HDAC1 | DLX1 | RBM42 | CENPB | LTF | PAX9 | ... | MEF2B | EGR1 | None | None | None | None | None | None | None | None |
10977 rows × 22 columns
Step 5 : Generating a set of common sub paths (or the context) for all root nodes#
In the table of paths above, we observe many unique genes appear as root nodes. Since we train the decision trees to predict the same target gene, the leaf nodes for all paths are the same.
We can thus consider these paths as potential regulatory links, where genes at the root regulates the target. All the genes at the root become potential regulators or the target. However, note that there are multiple intermediate nodes between the root and the target. Comparing these
We consider the root nodes as potential regulators of the target gene and to find if they are co regulators, we compare how similar the intermediate nodes are in between 2 unique root nodes.
pathset = coregtor.create_context(all_paths)
pathset.keys()
dict_keys(['HMBOX1', 'MEIS1', 'NMRAL1', 'ZNF18', 'NFYB', 'HCLS1', 'IRF9', 'DPRX', 'ANXA1', 'YBX1', 'ZNF485', 'ALX3', 'TBX19', 'TAGLN2', 'ZNF768', 'PHF21A', 'SP110', 'ATOH8', 'FOXB2', 'BRCA1', 'ID1', 'ZSCAN16', 'MXI1', 'EEF1D', 'CXXC1', 'ZNF846', 'ZNF624', 'AIRE', 'FOXO4', 'ZNF577', 'NKX6-2', 'FEZ1', 'ZNF837', 'ZNF114', 'HNRNPUL1', 'BCL6', 'ZBTB17', 'ZNF652', 'ZNF692', 'HDAC1'])
Step 6 : Comparing context of all root nodes with each other#
similarity
# transforming the context into a more comparable representation
gf_histogram = coregtor.transform_context(pathset,method="gene_frequency")
gf_histogram
| SP110 | GATA2 | DBX2 | VENTX | ETS1 | ZFP64 | ZNF284 | OLIG2 | ZBTB20 | RBPJ | ... | ZFP30 | AGMAT | ATF2 | KLF14 | ZBTB41 | ZNF773 | SETDB1 | DBX1 | PHTF1 | ZNF789 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HMBOX1 | 647 | 55 | 79 | 58 | 7 | 1 | 1 | 26 | 26 | 5 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| MEIS1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 2 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| NMRAL1 | 69 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF18 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| NFYB | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| HCLS1 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| IRF9 | 0 | 0 | 3 | 3 | 0 | 0 | 1 | 0 | 8 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| DPRX | 135 | 0 | 0 | 54 | 3 | 2 | 0 | 4 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ANXA1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| YBX1 | 141 | 27 | 22 | 24 | 3 | 0 | 2 | 0 | 17 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF485 | 0 | 7 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ALX3 | 1 | 40 | 0 | 0 | 0 | 0 | 1 | 0 | 2 | 10 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| TBX19 | 138 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 5 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| TAGLN2 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF768 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| PHF21A | 1 | 0 | 0 | 27 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| SP110 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 4 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ATOH8 | 0 | 0 | 0 | 26 | 0 | 0 | 0 | 0 | 45 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| FOXB2 | 75 | 0 | 6 | 3 | 0 | 0 | 0 | 3 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BRCA1 | 14 | 0 | 5 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ID1 | 72 | 0 | 0 | 0 | 0 | 0 | 0 | 31 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZSCAN16 | 120 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| MXI1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| EEF1D | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CXXC1 | 0 | 0 | 0 | 45 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF846 | 133 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF624 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AIRE | 55 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| FOXO4 | 65 | 1 | 9 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF577 | 72 | 0 | 21 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| NKX6-2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| FEZ1 | 72 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 22 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF837 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ZNF114 | 56 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| HNRNPUL1 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 | 5 | 0 | ... | 3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BCL6 | 1 | 34 | 0 | 0 | 2 | 0 | 0 | 2 | 1 | 0 | ... | 1 | 0 | 9 | 2 | 1 | 2 | 2 | 0 | 0 | 0 |
| ZBTB17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 0 |
| ZNF652 | 80 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| ZNF692 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| HDAC1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
40 rows × 1820 columns
sim_matrix = coregtor.compare_context(gf_histogram,"cosine")
sim_matrix.to_csv("sample_sim.csv",index=False)
Step 7 : Interactive generation of co-regulating gene clusters#
# Dendrogram
ut.plot.dendrogram(sim_matrix)
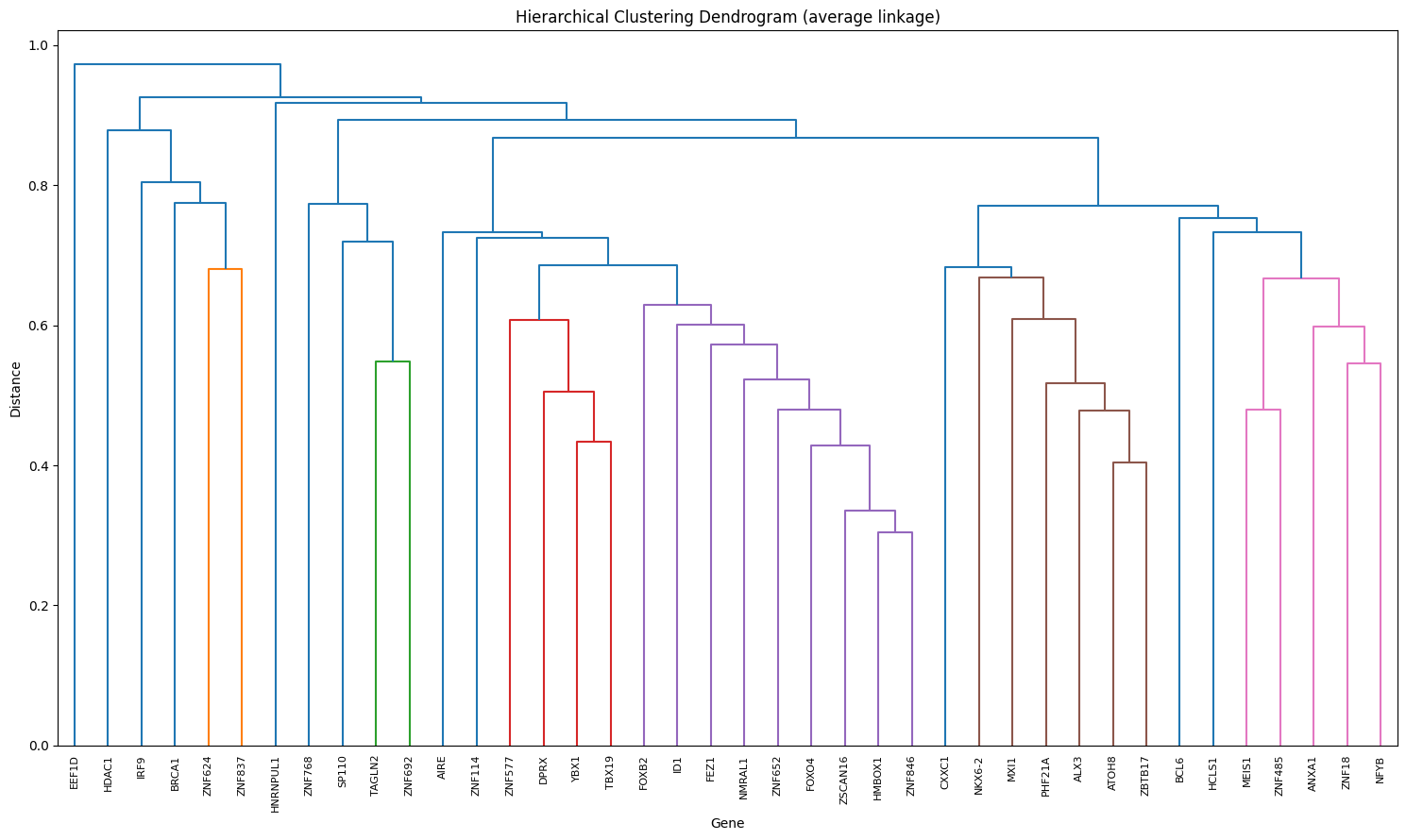
(<Figure size 1500x900 with 1 Axes>,
<Axes: title={'center': 'Hierarchical Clustering Dendrogram (average linkage)'}, xlabel='Gene', ylabel='Distance'>,
array([[ 0. , 25. , 0.30382494, 2. ],
[21. , 40. , 0.33554309, 3. ],
[17. , 36. , 0.40435524, 2. ],
[28. , 41. , 0.42812026, 4. ],
[ 9. , 12. , 0.43370955, 2. ],
[11. , 42. , 0.47806197, 3. ],
[ 1. , 10. , 0.47909859, 2. ],
[37. , 43. , 0.4797432 , 5. ],
[ 7. , 44. , 0.50478485, 3. ],
[15. , 45. , 0.51685424, 4. ],
[ 2. , 47. , 0.52217979, 6. ],
[ 3. , 4. , 0.54517594, 2. ],
[13. , 38. , 0.54869611, 2. ],
[31. , 50. , 0.57270583, 7. ],
[ 8. , 51. , 0.597578 , 3. ],
[20. , 53. , 0.60119813, 8. ],
[29. , 48. , 0.60694411, 4. ],
[22. , 49. , 0.60943375, 5. ],
[18. , 55. , 0.6294707 , 9. ],
[46. , 54. , 0.66667679, 5. ],
[30. , 57. , 0.66767775, 6. ],
[26. , 32. , 0.67994462, 2. ],
[24. , 60. , 0.68286585, 7. ],
[56. , 58. , 0.686368 , 13. ],
[16. , 52. , 0.72010222, 3. ],
[33. , 63. , 0.72538881, 14. ],
[27. , 65. , 0.73288874, 15. ],
[ 5. , 59. , 0.73338946, 6. ],
[35. , 67. , 0.75371378, 7. ],
[62. , 68. , 0.77129978, 14. ],
[14. , 64. , 0.77281854, 4. ],
[19. , 61. , 0.77514362, 3. ],
[ 6. , 71. , 0.80443734, 4. ],
[66. , 69. , 0.86792962, 29. ],
[39. , 72. , 0.87816609, 5. ],
[70. , 73. , 0.89315843, 33. ],
[34. , 75. , 0.91820863, 34. ],
[74. , 76. , 0.92527178, 39. ],
[23. , 77. , 0.97238938, 40. ]]))
# Cophonetic distance
ut.plot.cophenetic(sim_matrix,methods=["average"])
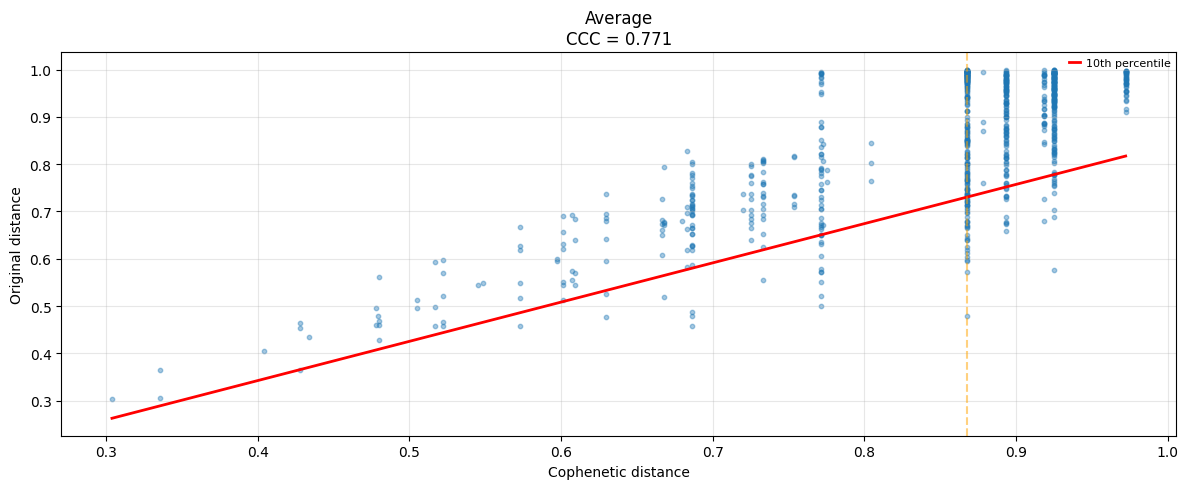
(<Figure size 1200x500 with 1 Axes>,
[<Axes: title={'center': 'Average\nCCC = 0.771'}, xlabel='Cophenetic distance', ylabel='Original distance'>],
{'average': np.float64(0.7708075282302238)},
np.float64(0.7304958606121552))
# generate results
results = coregtor.identify_coregulators(sim_matrix,target_gene=target_gene_name,distance_threshold=0.70)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[17], line 3
1 # generate results
----> 3 results = coregtor.identify_coregulators(sim_matrix,target_gene=target_gene_name,distance_threshold=0.70)
File ~/projects/coregtor/src/coregtor/clusters.py:429, in identify_coregulators(comparison_matrix, target_gene, clustering_method, auto_threshold_method, **kwargs)
422 return {
423 "model": None, # SciPy-based (more efficient)
424 "clusters_df": clusters_df,
425 "best_cluster": best_cluster
426 }
428 # Manual clustering path
--> 429 result = CLUSTERING_METHODS[clustering_method]["method"](
430 comparison_matrix, target_gene, **kwargs
431 )
432 result["best_cluster"] = None
433 return result
File ~/projects/coregtor/src/coregtor/clusters.py:235, in _identify_coregulators_hierarchical(comparison_matrix, target_gene, n_clusters, distance_threshold, linkage, min_module_size, **kwargs)
232 clustering_params["distance_threshold"] = distance_threshold
234 model = AgglomerativeClustering(**clustering_params)
--> 235 labels = model.fit_predict(dist_matrix)
237 # Build cluster assignments
238 gene_clusters = pd.DataFrame({
239 'gene': comparison_matrix.index.astype(str),
240 'cluster_id': labels
241 })
File ~/Library/Caches/pypoetry/virtualenvs/coregtor-uBpjneWK-py3.12/lib/python3.12/site-packages/sklearn/cluster/_agglomerative.py:1116, in AgglomerativeClustering.fit_predict(self, X, y)
1095 def fit_predict(self, X, y=None):
1096 """Fit and return the result of each sample's clustering assignment.
1097
1098 In addition to fitting, this method also return the result of the
(...) 1114 Cluster labels.
1115 """
-> 1116 return super().fit_predict(X, y)
File ~/Library/Caches/pypoetry/virtualenvs/coregtor-uBpjneWK-py3.12/lib/python3.12/site-packages/sklearn/base.py:695, in ClusterMixin.fit_predict(self, X, y, **kwargs)
672 """
673 Perform clustering on `X` and returns cluster labels.
674
(...) 691 Cluster labels.
692 """
693 # non-optimized default implementation; override when a better
694 # method is possible for a given clustering algorithm
--> 695 self.fit(X, **kwargs)
696 return self.labels_
File ~/Library/Caches/pypoetry/virtualenvs/coregtor-uBpjneWK-py3.12/lib/python3.12/site-packages/sklearn/base.py:1365, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)
1358 estimator._validate_params()
1360 with config_context(
1361 skip_parameter_validation=(
1362 prefer_skip_nested_validation or global_skip_validation
1363 )
1364 ):
-> 1365 return fit_method(estimator, *args, **kwargs)
File ~/Library/Caches/pypoetry/virtualenvs/coregtor-uBpjneWK-py3.12/lib/python3.12/site-packages/sklearn/cluster/_agglomerative.py:991, in AgglomerativeClustering.fit(self, X, y)
973 """Fit the hierarchical clustering from features, or distance matrix.
974
975 Parameters
(...) 988 Returns the fitted instance.
989 """
990 X = validate_data(self, X, ensure_min_samples=2)
--> 991 return self._fit(X)
File ~/Library/Caches/pypoetry/virtualenvs/coregtor-uBpjneWK-py3.12/lib/python3.12/site-packages/sklearn/cluster/_agglomerative.py:1010, in AgglomerativeClustering._fit(self, X)
1007 memory = check_memory(self.memory)
1009 if not ((self.n_clusters is None) ^ (self.distance_threshold is None)):
-> 1010 raise ValueError(
1011 "Exactly one of n_clusters and "
1012 "distance_threshold has to be set, and the other "
1013 "needs to be None."
1014 )
1016 if self.distance_threshold is not None and not self.compute_full_tree:
1017 raise ValueError(
1018 "compute_full_tree must be True if distance_threshold is set."
1019 )
ValueError: Exactly one of n_clusters and distance_threshold has to be set, and the other needs to be None.
results
((AgglomerativeClustering(distance_threshold=0.7, linkage='average',
metric='precomputed', n_clusters=None),
target_gene gene_cluster n_genes \
0 GFAP BCL6,DPRX,FOXB2,HMBOX1,IRF9,NR5A2,PHF21A,PRRX1... 16
1 GFAP ALX3,CXXC1,HCLS1,HDAC1,NEUROG2,NKX6-2,NMRAL1,P... 12
2 GFAP PPP2R3B,ZNF536,ZNF775 3
3 GFAP BBX,ZNF814 2
4 GFAP UBXN1,ZKSCAN1 2
cluster_id
0 0
1 3
2 2
3 1
4 4 ),
None)
clusters
(AgglomerativeClustering(distance_threshold=0.7, linkage='average',
metric='precomputed', n_clusters=None),
target_gene gene_cluster n_genes \
0 GFAP BCL6,DPRX,FOXB2,HMBOX1,IRF9,NR5A2,PHF21A,PRRX1... 16
1 GFAP ALX3,CXXC1,HCLS1,HDAC1,NEUROG2,NKX6-2,NMRAL1,P... 12
2 GFAP PPP2R3B,ZNF536,ZNF775 3
3 GFAP BBX,ZNF814 2
4 GFAP UBXN1,ZKSCAN1 2
cluster_id
0 0
1 3
2 2
3 1
4 4 )
import importlib
importlib.reload(coregtor)
<module 'coregtor' from '/Users/svj/projects/coregtor/src/coregtor/__init__.py'>
results1 = results1[results1["n_genes"]<10]
results1
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[35], line 1
----> 1 results1 = results1[results1["n_genes"]<10]
2 results1
TypeError: tuple indices must be integers or slices, not str
results2,_ = coregtor.identify_coregulators(sim_matrix,target_gene=target_gene_name,distance_threshold=0.75)
results2
| target_gene | gene_cluster | n_genes | cluster_id | |
|---|---|---|---|---|
| 0 | GFAP | ALX3,CREB3L2,DPRX,FOXB2,HCLS1,HMBOX1,ID1,IKZF2... | 19 | 0 |
| 1 | GFAP | CLK1,IRF9,NKX6-2,PIR,RAD21,TBX19,ZNF768,ZNF837 | 8 | 3 |
| 2 | GFAP | POU2AF1,SMC3,ZRSR2 | 3 | 2 |
| 3 | GFAP | MAFK,ZNF577 | 2 | 1 |
| 4 | GFAP | BCL6,MXI1 | 2 | 4 |
| 5 | GFAP | FEZ1,HTATIP2 | 2 | 5 |
results2 = results2[results2["n_genes"]<10]
results2
| target_gene | gene_cluster | n_genes | cluster_id | |
|---|---|---|---|---|
| 1 | GFAP | CLK1,IRF9,NKX6-2,PIR,RAD21,TBX19,ZNF768,ZNF837 | 8 | 3 |
| 2 | GFAP | POU2AF1,SMC3,ZRSR2 | 3 | 2 |
| 3 | GFAP | MAFK,ZNF577 | 2 | 1 |
| 4 | GFAP | BCL6,MXI1 | 2 | 4 |
| 5 | GFAP | FEZ1,HTATIP2 | 2 | 5 |